大多数新的 深度学习 发布的模型, 尤其是在自然语言处理方面,非常非常大:它们的参数范围从数亿到 数百亿.
如果有足够好的架构, 模型越大,它的学习能力就越大. 因此,这些新模型具有巨大的学习能力和训练能力 非常非常大的数据集.
正因为如此,他们学习了他们所训练的数据集的整个分布. 可以说它们对这些数据集的压缩知识进行了编码. This allows these 模型 to be used for very interesting applications—the most common one being 转移学习. 迁移学习是对预先训练好的模型进行微调 自定义数据集/任务, which requires far less data, 和 模型 converge very quickly compared to training from scratch.
虽然预训练模型也用于计算机视觉, 本文将重点介绍它们在 自然语言处理 (NLP)域. 变压器结构 在这些模型中使用的是最常见和最强大的体系结构吗.
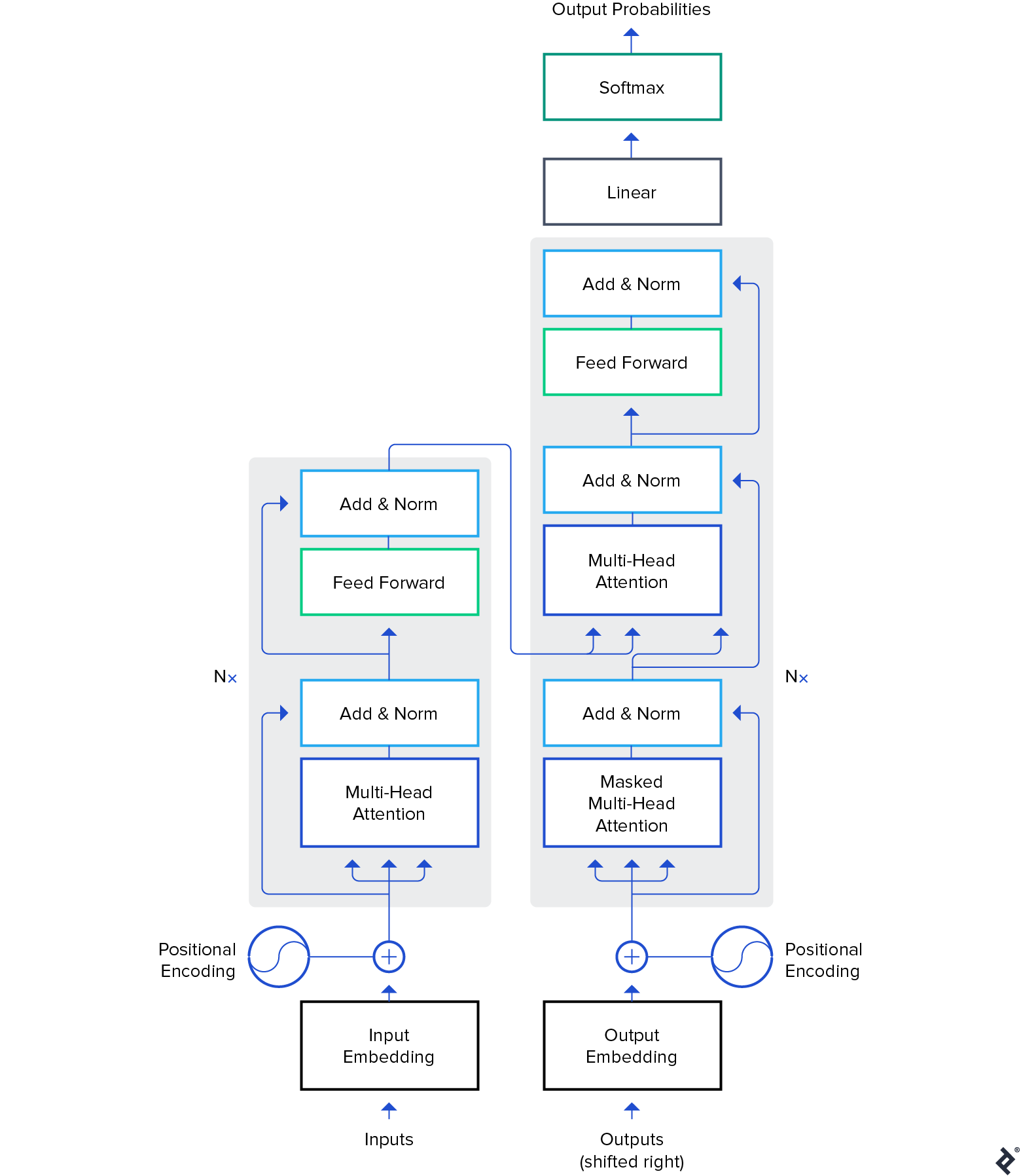
虽然 伯特 开始了NLP迁移学习的革命,我们将探讨 GPT-2 和 T5 模型. These 模型 are pre-trained—fine-tuning them on specific applications will result in much better evaluation metrics, 但我们将使用它们的开箱即用, i.e.,没有任何微调.
GPT-2在2019年发布时引起了相当大的争议. 既然是 非常擅长生成文本,它吸引了相当多的 媒体的关注 并提出了很多关于人工智能未来的问题.
GPT-2是在40gb文本数据上训练的 很大的模型 包含一个 大量的压缩知识 从互联网的横截面.
GPT-2有很多 潜在用例. 它可以用来预测一个句子的概率. 这反过来又可以用于文本自动更正. 接下来,可以直接使用单词预测 构建自动完成组件 用于编写代码的IDE(如Visual Studio Code或PyCharm)以及 一般文本写作. 我们将使用它来自动生成文本, 大量的文本语料库可以用于自然语言分析.

像GPT-2这样的预训练模型的能力 生成连贯的文本 非常令人印象深刻. 我们可以给它一个前缀文本,然后让它生成下一个单词、短语或句子.
An example use case is generating a product 审查s dataset to see which type of words are generally used in positive 审查s versus negative 审查s.
让我们来看一些例子, 从我们得到的开始如果我们从正的前缀开始, “真的很喜欢这部电影!”
| 示例1 | 我喜欢这个角色在不断面临危险时的情绪, 以及他内心的恐惧是如何被这些事件慢慢克服的. Also loved that he is so focused on surviving; even for a while it felt like something out of 蝙蝠侠大战超人 was showing up every now again because you always knew your enemy would show up eventually anyways :) The ending theme really stuck with me too… I mean yeah they did have to… |
| 示例2 | 它做了我想做的事情,非常有趣. The cast was awesome 和 the story makes sense so far after seeing everything else already on IMDB. There are hints about being in an underground city from time immemorial due their “power” (or lack thereof) but they don’t really tell that much…I think its more like one big mystery then some other aspects coming together with me for now though….应该是…… |
如你所见,这个词 审查 前缀中没有任何地方吗, 但由于大多数评论都是标题后面跟着评论的主体, 这迫使模型适应这种分布. 还要注意对的引用 蝙蝠侠大战超人.
让我们看另一个例子. 而不是电影评论, 我们将尝试使用否定前缀生成产品评论, 垃圾产品! 不要买.”
| 示例1 | 请, do NOT try to use this as a fertilizer for your gardens or lawns – it will cause some serious water damage if ingested by fish 和 birds. Use with caution because of the possibility that pesticides may be present in pet foods available online at organic grocery stores such too “good” names like Petsmart, 宠物市场 & 西夫韦.食物垃圾的毒性有多大? 废物产生的影响相当大——甚至足够…… |
| 示例2 | 没人会再给你那种垃圾了. Just do yourself 和 your business a favor 和 clean up before buying it for nothing more than to save some money or convenience in the future.1/2盎司瓶塑料食品储存包装+ 1包#1636370105702615 (P, 3ml) $7 Buy Now You can purchase these bottles at any retail stores but here is how to get… |
再一次。, 前缀可以推断为产品评论的标题, 因此,模型开始按照该模式生成文本. GPT-2可以生成像这样的任何类型的文本.
A 谷歌Colab笔记本 已经准备好用于实验,就像“用变压器写”一样。 现场演示.
是的, 因为GPT-2是在网上训练的, 它“知道”到2019年为止在网上发表的许多人类知识. 它也可以用于情境问题, 但我们必须遵循“问题:X”的明确格式, 回答:“然后让它尝试自动完成。. 但如果我们强迫模型回答我们的问题,它可能会输出一个相当模糊的答案. Here’s what happens trying to force it to answer open-ended questions to test its knowledge:
| 示例1 | 问:谁发明了进化论? 答: 进化论最早是由查尔斯·达尔文于1859年提出的. |
| 示例2 | 问题:人类有多少颗牙齿? 答: 人类有21颗牙齿. |
As we can see, the pre-trained model gave a pretty detailed answer to the first question. 第二,它尽了最大的努力,但它不能与谷歌搜索相比.
很明显,GPT-2具有巨大的潜力. Fine-tuning it, it can be used for the above-mentioned examples with much higher accuracy. 但即使是我们评估的预训练GPT-2也没有那么糟糕.
谷歌的T5 是迄今为止最先进的自然语言模型之一吗. 一般来说,它是建立在以前关于Transformer模型的工作之上的. Unlike 伯特, which had only encoder blocks, 和 GPT-2, which had only decoder blocks, T5 uses 这两个.
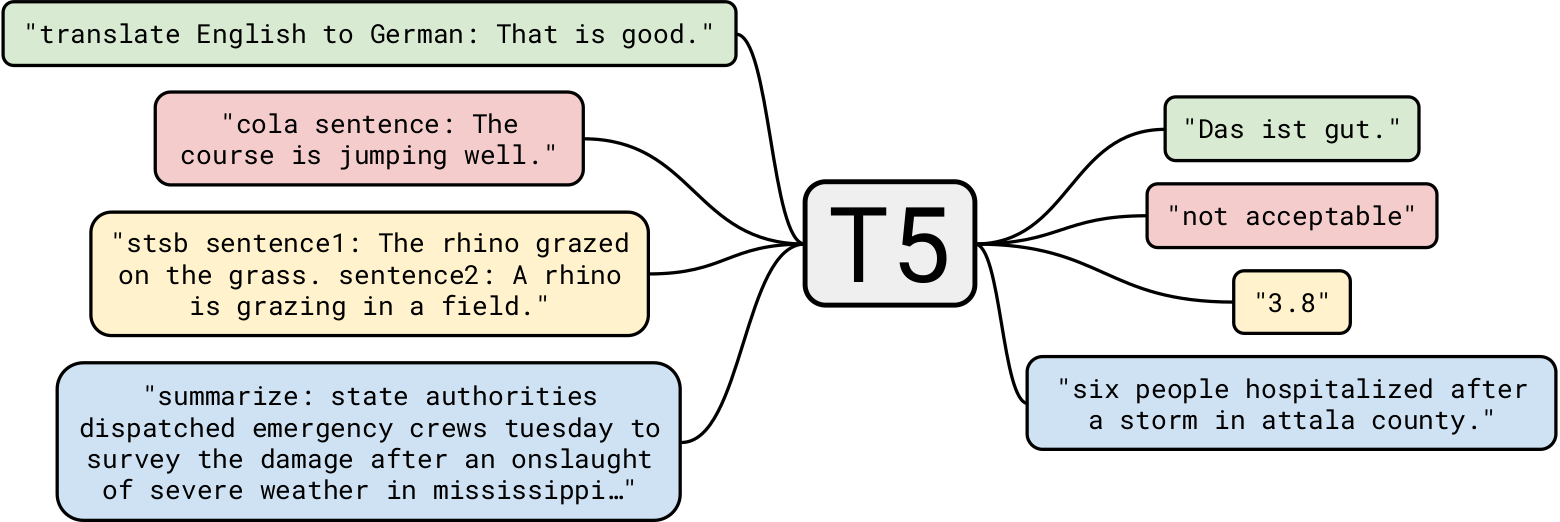
在40gb的文本数据上训练GPT-2已经令人印象深刻了,但是 T5是在一个7tb的数据集上训练的. 尽管它被训练成, 非常多的迭代, 它不能浏览所有的文本. 虽然T5可以做到 文本生成 像GPT-2一样,我们将把它用于更有趣的业务用例.
让我们从一个简单的任务开始: 文本摘要. 对于那些 人工智能开发公司 wanting to build an app that summarizes a news article, T5 is perfectly suited for the task. 例如,给予 这篇文章 到T5,这里有三种不同的总结:
| V1 | 命运2的下一个赛季,从3月10日开始,将重新制作剑 . 他们将有能量补充用于重型攻击和防御 . 情人节活动“深红日”也在本月举行 . |
| V2 | Bungie透露,《欧博体育app下载》下一季将大幅重制刀剑 . 对于这一季的剧情,制片方基本上是含糊其辞 . 重新思考将使剑部分绕过敌人的盾牌 . |
| V3 | 《欧博体育app下载》下一季将重制剑,让它们绕过敌人的盾牌 . 赛季从3月10日开始 . 你可以在情人节活动期间玩《欧博体育app下载》 . |
正如我们所看到的,它在总结文章方面做得非常出色. 而且,每个摘要都是不同的.
使用预训练模型进行总结具有巨大的潜在应用. One interesting use case could be to generate a summary of every article automatically 和 put that at the start for readers who just want a synopsis. 它还可以更进一步 个性化每个用户的摘要. 例如, 如果一些用户的词汇表较小, 他们可以得到一份不那么复杂的单词选择摘要. 这是一个非常简单的例子,但它展示了该模型的强大功能.
另一个有趣的用例是在网站的SEO中使用这样的摘要. 虽然T5可以训练生成非常高质量的SEO自动, 使用摘要可能会有帮助, 无需重新训练模型.
T5也可用于 阅读理解, e.g.,回答给定背景下的问题. 这个应用程序有非常有趣的用例,我们将在后面看到. 让我们从几个例子开始:
| 问题 | 谁发明了进化论? |
| 上下文 (Encyclopædia大英百科全书) | The discovery of fossil bones from large extinct mammals in Argentina 和 the observation of numerous species of finches in the Galapagos Isl和s were among the events credited with stimulating Darwin’s interest in how species originate. 1859年,他出版了《欧博体育app下载》, 建立进化论和进化论的论文, 最重要的是, 自然选择在决定其进程中的作用. |
| 回答 | 达尔文 |
书中没有明确提到达尔文发明了这个理论, but the model used its existing knowledge along with some context to reach the right conclusion.
在一个非常小的背景下呢?
| 问题 | 我们去了哪里?? |
| 上下文 | 在我生日那天,我们决定去巴基斯坦的北部地区. 真的很有趣. |
| 回答 | 巴基斯坦北部地区 |
好吧,这很简单. 来个哲学问题怎么样?
| 问题 | 生命的意义是什么? |
| 上下文 (维基百科) | The meaning of life as we perceive it is derived from 哲学的和宗教的沉思, 以及对存在的科学探究, 社会关系, 意识, 和幸福. 还涉及许多其他问题, 比如象征意义, 本体, 价值, 目的, 道德, 善与恶, 自由意志, 神的存在:一个或多个神的存在, 上帝的概念, 灵魂, 还有来世. Scientific contributions focus primarily on describing related empirical facts about the universe, 探索关于生命“如何”的背景和参数. |
| 回答 | 哲学的和宗教的沉思, 以及对存在的科学探究, 社会关系, 意识, 和幸福 |
虽然我们知道这个问题的答案很复杂, T5试图想出一个非常接近的办法, 明智的回答. 荣誉!
让我们更进一步. Let’s ask a few questions using the previously mentioned Engadget article as the context.
| 问题 | 这是怎么回事?? |
| 回答 | 《欧博体育app下载》将大幅重做 |
| 问题 | 我们什么时候可以期待这个更新? |
| 回答 | 3月10日 |
正如你所看到的,T5的上下文问题回答非常好. One business use case could be to build a contextual chatbot for websites that answers queries relevant to the current page.
另一个用例可能是从文档中搜索一些信息,例如.g., ask questions like, “Is it a breach of contract to use a company laptop for a personal project?使用法律文件作为上下文. 尽管T5有其局限性,但它非常适合这类任务.
读者可能会想, 为什么不为每个任务使用专门的模型呢? It’s a good point: The accuracy would be much higher 和 the deployment cost of specialized 模型 would be much lower than T5’s pre-trained NLP model. 但T5的美妙之处在于它是“一个模式来统治所有”.e.,你可以使用一个预训练模型 几乎适用于任何NLP任务. 另外,我们想要使用这些开箱即用的模型,而不需要再训练或微调. 所以对于开发者来说,创建一个总结不同文章的应用程序, 还有一个应用程序,可以根据上下文回答问题, 同样的T5型号可以做这两件事.
在本文中, we explored pre-trained 模型 和 how to use them out of the box for different business use cases. 就像经典的排序算法一样,它几乎无处不在地用于排序问题, 这些预训练的模型将被用作标准算法. 很明显,我们所探索的只是 触及表面 这些模型可以做更多的事情.
预训练的深度学习模型,比如 StyleGAN-2 和 DeepLabv3 以类似的方式, 计算机视觉的应用. 我希望你喜欢这篇文章,并期待在下面听到你的评论.
Pre-training is a technique where data scientists train a model architecture on a very large dataset. This induces prior knowledge to the model 和 helps in fine-tuning the model for newer tasks. 一个例子是在ImageNet上训练Resnet-50.
训练模型是在数据集上训练的特定模型体系结构.
Each 深度学习 model is built using a set of basic layers that are connected in different ways. 这些层的连接创建了一个特定的模型体系结构. 示例架构有ResNet、GPT-2和StyleGAN.
A 深度学习 layer is a mathematical operation that transforms the output of the previous layer into the input for the next layer. There are usually numerical parameters associated with these mathematical operations which are learned during training.
The weights of a 深度学习 model are a list of the 价值s of all parameters of that model associated with each of its layers.
世界级的文章,每周发一次.
世界级的文章,每周发一次.



 authors are vetted experts in their fields 和 write on topics in which they have demonstrated experience. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.
authors are vetted experts in their fields 和 write on topics in which they have demonstrated experience. 我们所有的内容都经过同行评审,并由同一领域的Toptal专家验证.